Poro Pathfinder Q-Learning in Malmo
Video link: https://www.youtube.com/watch?v=7FZ7O4REYaA&feature=youtu.be
Project Summary
The goal of our AI is to create a self-learning, pathfinding AI that uses continuous movement to make its way to a target location. It should be able to jump up hills and climb mountains to it’s goal if neccessary, but also find quick and efficient paths towards the goal on flat land. The AI uses reinforment learning (q-learning) to gradually learn an optimal policy.
The AI is to have reasonable performance, but not to the same level as A* or even dijkstra’s algorithm. However, this AI will outperform the mentioned Algorithms in memory constraints and scalability. It only requires its immediate surroundings, coordinates of itself, and its goal, as opposed to the entire world. As a result, in endless worlds where regular pathfinding algorithms would fail, this AI will still perform adequately.
Approach
The AI uses q-learning. Specifically, it creates a q-table in which for each state, lists the expected reward for each action that can be done in that state. The rewards are initially 0 and the q-table is learned by randomly selecting actions in the beginning. As some q values change, the AI selects the highest q-value action in the current state a majority of the time (with 1-epsilon probabilty) and randomly chooses a random action with epsilon probablity. The q table is updated using the following formula in the case where future actions do not propagate down and affect the currect q value.
Q(s,a) = Q(s,a) + alpha( gamma( reward of a + q value of next action) - Q(s,a) )
where gamma and alpha are user specified variables. Alpha affects how quickly Q values change and Gamma affects the weight of the current reward and expected reward.
Our AI also uses a variable n which specifies how many actions in the future a q-value is affected by. (if n = 100, q(s,a) will be affected by the rewards of a(t+1), a(t+2), …, a(t+100), and Q(s(t+100), a(t+100)). The equation is therefore:
Q(s,a) = Q(s,a) + alpha( rewards + gamma^n(q value of nth action from current action) - Q(s,a) )
where rewards is the sum from i =0, to i = n of gamma^i * reward(a(t+i)).
States:
The states of this AI can be split into 2 distinct parts. The first is the features of the 4 adjacent blocks. Each of these blocks has a value of either drop, flat, hill, or wall. This is mainly to help the AI figure out how to move up and down elevations. As the demo current does not contain any hills or mountains, this part mainly serves as a placeholder.
The second and most important part of the state definition is a variable (N,E,S,W) that determines the general direction the goal is from the AI.
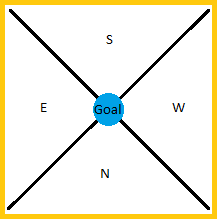
The above figure shows the approximation the AI uses to determine the general direction to the goal, depending on which quadrant the AI currently resides in. This means, for example, if the agent was to the south of the goal, the variable would be set as N (for North). However, for example, if the agent was to the southeast of the goal, the variable would be set as W if the x-coordinate distance to the goal is bigger than the z-coordinate distance to the goal. If the z-coordinate distance to the goal is bigger than the x-coordinate distance to the goal, the variable would be set as N.
This approximation is the core to the AI because it limits the state space, giving the AI just enough information to make its way to the goal, but not encumbering it with an excess number of states. By limiting the number of states, the AI is able to learn, and then recognize a few, specific situations, as opposed to learning optimal actions in every single tile of the world or some other unreasonable metric.
Reward:
The reward acts as both a rating of the AI as well as helping the AI learn ideal actions for each state. The way the reward is determined is by measuring the change in a straight line distance from the AI to the goal between actions. A negative constant (c) is then added on to the reward to teach the AI not to do stagnant actions (such as walking into a wall).
Reward for an action = oldDistance from goal - newDistance from goal - c
The AI also receives a reward for reaching its goal (touching its goal).
This reward scheme promotes actions that help the agent progress towards the goal, while punishing actions that distance the agent from the goal. The AI is thus able to quickly learn favorable actions.
Tying It Together:
Whenever the AI takes an action, it uses the reward gained or lost to rate the performance of the action, making it more likely to do the action in the future if the reward was positive. Conversely, actions that result in negative rewards are less likely to be done in the future. On top of this, the AI also rates the action based on the expected value of the next state/action pair, which propagates down to previous actions. Because of this, even though an action may have an immediate, negative reward, it may still be chosen in the future if the resulting state generally performs well. The AI learns from each action, which carries over from trial to trial, resulting in relatively consistant performance as trials progress.
Evaluation
The total reward is a function of the distance traveled, a base reward for reaching the goal, and the number of actions taken (n).
Total Reward = Goal reward + start distance from goal - n * negative reward for action
Based on the above formula, the reward is inversely proportional to the number of actions taken to reach the goal. As such, the AI’s performance is evaluted by inspecting the reward of different trials of the course of the learning process. (Higher reward = less actions taken = Better Performance)
The above graph shows that the AI works more or less as expected. During the first trial, it has no information about its expected rewards for each state/action pair, so it requires a couple of actions to realize the optimal action. This performance is expected due to the generalized states. The AI only needs to learn actions for each state rather than each position the agent is at. From then on, the reward is relatively consistant as the AI has already learned how to navigate to the goal. Small variances between trials is expected due to the greedy epsilon algorithm which causes the AI to occasionally choose non-optimal solutions.
There is some sort of abnormality during trials 9 and 10, which may be due to the epsilon greedy algorithm or because the AI enters a state it is unfamiliar with. More testing is required to solve this issue. Regardless, the algorithm is able to reach the optimal reward again within a couple of trials due to the reward function punishing bad actions. This shows that at the very least, the reward function works as intended.
Remaining Goals/Challenges
As of now, the AI has not reached its goal of traversing mountains and hills. Its action space is currently very limited, making the AI unable to jump. The AI’s performance has also not been tested with obstacles that it must navigate around or through.
Ideally, the AI needs to be tested and have sufficient performance in such cases. To do so, additional actions must be added as well as pruning some actions depending on the state. For example, when facing a wall, the forward move action should be pruned from the action space to prevent the AI from stagnating.
Currently it is unknown how difficult it will be to adapt the AI to handle obstacles and to handle actions at different elavations. It is difficult to say whether it will be a progress block or testing. One concern however, is that the AI sometimes unlearns optimal actions for a state which is not expected performance and will be possibly difficult to debug.